
Project Goal: To significantly reduce data collection costs and improve safety for reward design
- Reward function design is essential for AI-based driving decision making; driving decisions depend on many factors combined, including travel time, safety, risk mitigation, …
- Inverse reinforcement learning (IRL) is widely used to find good reward function, based on very costly data collection. E.g., Waymo has collected about 20+ million miles over many years.
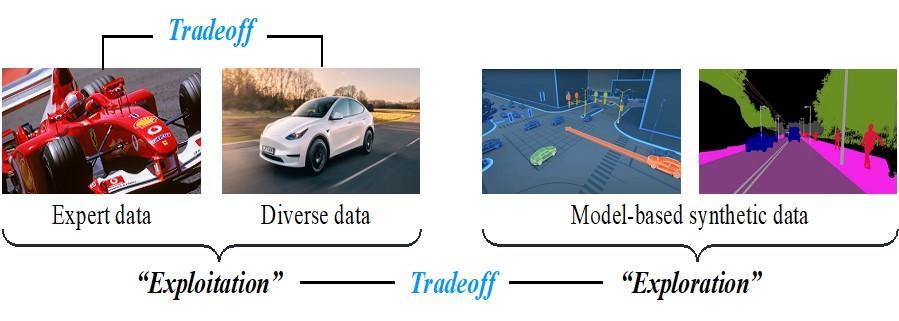
Research design: We will address the challenge of how to learn good reward function from diverse sources of data:
- Higher-quality “expert” data (very costly)
- Lower-quality “diverse” data (cheaper and plenty of)
- Develop conservative reward learning via offline IRL to minimize reward extrapolation error.